


Essential features of an Event Store for Event Sourcing
An Event Store, whether it is an out-of-the-box solution or custom-built, needs to offer certain essential features and might offer some additional, advanced features.

In this article, I will focus on the essential features that make an Event Store different from traditional, stateful storage solutions. I will not cover features that are common to all database systems, such as good read and write performance or access controls for security. Instead, I will discuss the features that are specific to Event Stores, and conclude with some advanced features in a second article.
As with my previous articles on this topic, the information in this article is based on my current knowledge and beliefs, without conducting additional research. There are already many excellent articles on this topic that may be better than mine, but I believe it is important to consider a variety of perspectives in order to form one’s own understanding. I asked my social media connections for their thoughts (just bullet points) and incorporated some of their feedback into this article.
What is Event Sourcing at all?
If you are new to the topic and need to start with the basics, you may find my previous article helpful:

Essential features
Now that the introduction is out of the way, let’s discuss the essential features of a production-grade Event Store. These are the features that make an Event Store different from traditional storage solutions and are necessary for it to be used in a production environment.
Event stream creation and management
An Event Store needs to be able to organize events into streams, where a stream consists of all the events for one entity, aggregate, or workflow (I’ll use entity in the following for simplicity). To do this, it typically uses the concept of a streamID — all events in one stream share a streamID so that the Event Store can offer operations like appending events to a stream and retrieving all events of a stream. Advanced Event Stores may also support creating and deleting streams explicitly, which is logically equivalent to adding a first event of a stream or deleting all events of a stream. Such advanced systems will typically store some metadata about streams separately from the streams.
An example streamID for an event stream that deals about customer entities could be customer-b1149445-d97b-45ee-8fc7-51ab42cdeeb0 - so the type of stream + the primary, unique id of the entity.
Append only
As events are facts that have happened in the past, they should not be modified. Instead, to modify the state of an event-sourced entity, correction events can be appended to the stream. If events are modified or deleted, it is no longer possible to accurately determine how an entity arrived at its current state. This is why an Event Store must store events in a durable and append-only manner, ensuring their integrity and immutability.
💡 While there may be some use-cases where it is necessary to archive and remove old events from a stream, such cases are special and should only be done for very specific and well-justified reasons, but not to correct faulty event streams.
Versioning an event stream
An event stream should have a version number, which allows for the ordering of events within a stream. In a custom implementation, this might be a simple sequential number starting from 1 (for the first event in the stream). For example, if a stream contains 10 events, its current version would be 10.
Professional Event Stores often use a commit version instead, which is a global version number that applies to all events in all streams. Versioning is a crucial feature, as it allows for the efficient and accurate replay of events in the correct order and enable concurrency control. The next paragraphs will explain this in more detail.
An event stream with a streamID, the stream has version 6, the next appended event will change the version to 7. The already existing events are “immutable”.

Concurrency control — ideally optimistic
The decisions that lead to appending one or more events to a stream are based on the current state of the system, as represented by the current version of an event stream. When a command is received that requests a change to the state (by creating one or more new events), it is evaluated based on the state at the current stream version. The new event(s) should only be appended if the stream is still at the expected version; otherwise, a concurrency conflict has occurred. If this feature is missing, the decision-making process (validating the command against the business rules) will be based on outdated state and may be incorrect if another event has significantly changed the state. This strategy is called optimistic concurrency control.
There are different options for handling concurrency conflicts. The simplest approach, which is often sufficient, is to retry the read-decide-write cycle. A more complex approach is to propagate the conflict to the users of the application, allowing them to make a new decision based on the updated state of the system.
In the absence of optimistic concurrency control, a fallback option is to use pessimistic concurrency control, which involves placing a write lock on the event stream before the read operation begins and releasing it only after the write operation has been completed. This can be efficient in systems with low contention, where the probability of concurrent changes to the same stream is low. However, in systems with high contention, locking can significantly degrade performance.
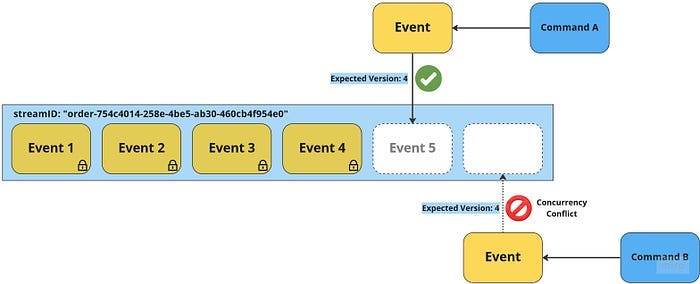
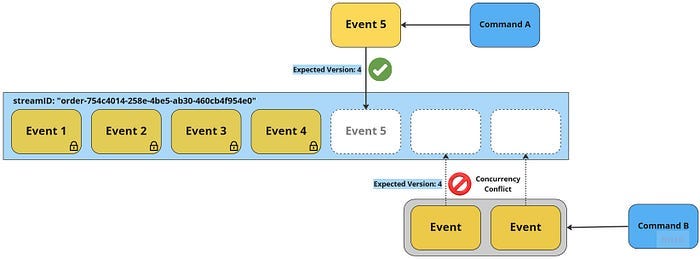
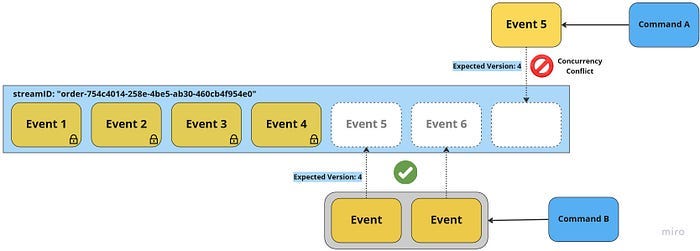
Atomically appending multiple events
Depending on the granularity of events, a single command may result in multiple events being written to the Event Store. In such cases, it is essential that the Event Store be able to append all of these events atomically — either all of the events are written, or none of them are. This ensures that the system does not lose information or end up in an invalid state. To support this functionality, an Event Store needs to have some form of transactional semantics. This allows for the atomic writing of multiple events, ensuring the consistency and integrity of the system.
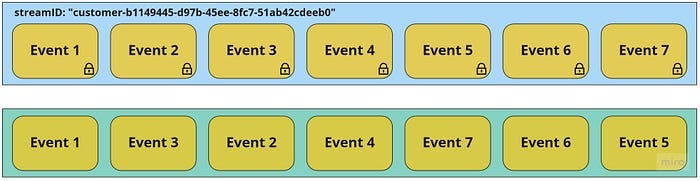
Event retrieval in order of occurrence
When events are read from an Event Store, it is essential that they are retrieved in the order in which they occurred. This is necessary to ensure that the projection of the current state is accurate and valid. Consider the following example, where two events are retrieved in the wrong order:
{
"eventType": "CustomerEmailAddressChanged"
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"emailAddress": "jane.doe@acme.corp"
"version": 5
}
{
"eventType": "CustomerEmailAddressChanged"
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"emailAddress": "jane.doe@example.org"
"version": 3
}In this case, our customer would expect emails to be sent to their ACME Corp account, not their old example.org address.
A comprehensive Event Store should also allow for the reading of events from multiple streams, such as all events in the store or all events of one or more specified types. This is useful in applications with a large reporting model that needs to project many different event types from multiple streams. In order to properly sort these events, the Event Store must also provide a global ordering of all events, in addition to the ordering within individual streams.
It is important to note that timestamps are not reliable for ordering events. Even if an application does not store 100000 events per second and the resolution is in nanoseconds, computer clocks are not always accurate, especially when running on multiple nodes. Time is a complex concept, and even if clocks are in sync, they can be affected by phenomena such as leap seconds.
While it is possible to handle versioning of single streams in the application logic, it is not possible to do so across streams. Therefore, the Event Store should handle version numbers and provide the necessary ordering of events to ensure that they are always retrieved in the correct order.
Storage and retrieval capabilities
The amount of data that an Event Store will need to store depends on various factors, such as whether it is a part of a microservices architecture (with one Event Store per service) or a monolithic application (with a shared Event Store), the granularity and size of events, the system throughput, and whether event streams can be archived after a certain period of time.
Event-sourced applications typically require more storage space than stateful systems, so an Event Store should be able to store large amounts of data and have the capacity to scale easily through sharding or other means.
The performance of an Event Store, especially the read performance, should be close to linear, regardless of how much data it contains. This is typically not difficult to achieve, as reading an event stream is ususally a primary index query. However, if an Event Store is implemented on a relational database management system (RDBMS) in a way that requires joining multiple tables, performance may be affected.
A stateful representation of a Customer entity stored as JSON:
{
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"emailAddress": "jane.doe@acme.corp",
"givenName": "Jane",
"familyName": "Doe",
"isEmailAddressConfirmed": true,
"lastChanged": "2022-12-15T11:50:27+0000"
}The same Customer stored as events, with a relatively short history. The events contain some possible metadata:
[
{
"eventType": "CustomerRegistered",
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"emailAddress": "jane.doe@example.com",
"givenName": "Jane",
"familyName": "Doe",
"version": 1,
"messageID": "c5351183-46da-46d1-984c-a6360d32dbdf",
"occurredAt": "2022-12-15T11:47:18+0000"
},
{
"eventType": "CustomerEmailAddressConfirmed",
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"version": 2,
"messageID": "0a387a38-05e6-4779-a20b-604bf0451763",
"occurredAt": "2022-12-15T11:49:59+0000"
},
{
"eventType": "CustomerEmailAddressChanged",
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"emailAddress": "jane.doe@acme.corp",
"version": 3,
"messageID": "2580b15d-a93d-47e9-864f-a44671262c6c",
"occurredAt": "2022-12-15T11:50:13+0000"
},
{
"eventType": "CustomerEmailAddressConfirmed",
"id": "b1149445-d97b-45ee-8fc7-51ab42cdeeb0",
"version": 4,
"messageID": "af4fc789-dcdd-4b38-8453-0921efea8e15",
"occurredAt": "2022-12-15T11:50:27+0000"
}
]Final words
I was somehow inspired to write this piece after I wrote that article:
Event Sourcing: Why Kafka is not suitable as an Event Store
If you read it, you will find a lot of overlap between the two. The perspective for this new article is different (positive) and it describes more features for Event Stores and in more detail. The Kafka article might help to understand some parts better, I can only recommend to read it.
I also want to suggest this excellent article from Yves about the same topic:
Requirements for the storage of events
💡 Disclaimer
Please note that I have mentioned EventStoreDB in this article and have written a paid article for their blog in the past. While I am not receiving any incentives for writing this piece, I do use and like their product. Additionally, I know several people who work or have worked for this company, some of whom I consider casual friends. As such, it is possible that my description of EventStoreDB features may be slightly biased.
Thank you for your time and attention! :-)
My article / subscriptions here are for free, but you can support my work by buying me a coffee.