
Implementing Domain-Driven Design and Hexagonal Architecture with Go (2)
How I implement tactical DDD patterns — the Domain layer

This article was originally published on Medium in 2020!
Disclaimer
Target audience for the articles in this series are people who are interested in Domain-Driven Design and Go with any knowledge level. I try to highlight where I deviate from idomatic Go or do things differently than in usual Go projects. In general I consider higher level concepts like Domain-Driven Design and Hexagonal Architecture to be “stronger” than “how most people implement things” in a programming language. Still I am always trying to balance both concerns and try to find a good compromise in cases. I will also describe simpler alternatives where applicable.
If you are religious about idiomatic Go and are not interested in different ways of doing things in Go — especially going the extra mile for defensive code and separation of concerns like Domain and Infrastructure — the articles in this series might not be for you!
Please be aware that the solutions I picked are just my decisions for the implementation of this playground project. I don’t want to suggest this as a blueprint architecture for any other projects implemented with Go! Still I hope that this article can offer some ideas and inspiration you as a reader find useful!
My personal Go code style and architectural style
There are a couple of things that are idiomatic in Go but I do differently in my private code. In a team setup, such decisions would be made together! Given all the lone wolf freedom I have, I just try to find good compromises between Go idiomatics and other concepts (see disclaimer above).
File name casing
One of the idiomatics I typically ignore is to use lowercase filenames instead of CamelCase (PascalCase precisely). Additionally, snake_case is only recommended to be used for certain special files, e.g. for tests (something_test.go) or CPU architectures (something_x86.go). Let’s say I implement a CustomerCommandHandler I would have to name the file customercommandhandler.go. I could also ignore the snake case rule and name it customer_command_handler.go. But for me personally, camel-case reads best — so I just use it. I am aware that this can cause problems on Windows with Git if a file is renamed from e.g. customerCommandHandler.go to CustomerCommandHandler.go. But this is not a Go specific issue.
Factory method names
Another best practice in Go is to name factory methods always NewSomething. I use that naming convention only for service type things like Application services or repositories. I ignore it for Domain type things and typically give them names that start with Build. There are multiple reasons why I do this.
That is best explained with an example. Given a Value Object EmailAddress which can be created from user input and reconstituted from persistence. So it obviously needs two factory methods. I could name them NewEmailAddress and NewEmailAddressFromPersistence. I want all my code to speak and it should tell the truth! In the “reconstitute from persistence” case “New” would be lying (IMHO). It was persisted to some data storage in some serialized form a while ago and now it is rehydrated — or reconstituted — but it’s certainly not “new”! I used Reconstitute… in the past. Due to issues with some non-native English speaker colleagues, I simplified this to Rebuild…, which admittedly suffers some information loss. A compromise.
func BuildEmailAddress(emailAddress string) EmailAddress {
// input validation would be executed here
return EmailAddress{value: emailAddress}
}
func RebuildEmailAddress(
emailAddress string,
isConfirmed bool,
) EmailAddress {
return EmailAddress{
value: emailAddress,
isConfirmed: isConfirmed,
}
}Short variable names
In Go, it’s encouraged to use short variable names if the usage of a variable is close to its declaration. I use speaking variable names almost everywhere — even if the usage is very close to the declaration.
emailAddress := BuildEmailAddress("john@example.com")
// do something with emailAddressinstead of
ea := BuildEmailAddress("john@example.com")
// do something with eaI often deviate from this in method receivers, so instead of(customerCommandHandler *CustomerCommandHandler)I might use (handler *CustomerCommandHandler) or even (h *CustomerCommandHandler)
The primary reason is that — for my taste — long receiver names draw to much attention away from function calls done in the code: customerCommandHandler.eventStore.AppendEvents(events []DomainEvents) vs. h.eventStore.AppendEvents(events []DomainEvents)
Factory methods and protecting invariants
My code is very defensive and might look too OOP-ish for fellow Go developers. E.g. I don’t allow to create anything without using a factory method. Some people who like Go for its simplicity just create structs like:
type EmailAddress struct {
Value string
IsConfirmed bool
}
emailAddress := EmailAddress{Value: "john@example.com"}Or at least make this possible with exposed (public) properties as in the example above. This is problematic because it makes it possible to create invalid objects:
emailAddress := EmailAddress{IsConfirmed: true}Value Objects and other types should not allow invalid state and might have to do input validation to protect their invariants, which can be bypassed if instantiation without factory methods is possible. I don’t want to invite anybody to use my code wrong, so I almost never expose the properties of structs. Naturally, inside the same package, everything is accessible. To reach ultimate privacy one would have to put every object into its own package which does not seem like a great idea.
It is totally valid to agree within a software development team to expose properties of objects and save the implementation of getter methods if the convention is to always use factory methods and mutation methods which guarantee that the invariants of those objects are protected. We all either do code reviews nowadays or even work in pair or mob programming mode so that bypassing factory methods would normally be detected. Such a decision totally depends on the team's size, experience, and other factors, but I personally have no reason to save those couple of lines of code. Any modern IDE (I am using Goland with love) can generate getter methods with two clicks.
func (emailAddress EmailAddress) String() string {
return emailAddress.value
}Functional cohesion
Let’s talk a bit about functional cohesion vs. logical cohesion. I have seen quite some Go code that is organized by logical cohesion — so the same types of things are close together, instead of having everything close together that is needed to fulfill a use-case. Those projects have a package structure like:
handler (all http handlers)
contract (all intermediate DTOs that validate input)
request (all http requests)
response (all http responses)
domain (all domain objects)
repository (all DB repositories)
If you follow a use-case through such a service you jump around in the directory structure between packages on the same level. As far as I can tell this is not even encouraged in the Go community. It might be useful in some types of projects but I never had a case where it made sense for me.
I like to organize my code using functional cohesion as much as possible and my primary heuristic for organizing the code is Hexagonal Architecture. I won’t dive into details in this article. As a teaser, my main packages or directories with sub-packages are Application, Domain, and Infrastructure. I’ll write at least one article in this series describing the details.
Data types, immutability, references, and pointer receiver methods
I will refer to the following types of objects as data types: Value Objects, Commands, Events, and the projected state of Entities / Aggregates.
Everything else is a service type (Application service, repositories, …) or a pure function. I already made this distinction before where I described naming conventions for factory methods. The Domain layer is built with such data types, functions, and possibly interface definitions for services (but no service implementations). All the data types should be immutable.
Immutability is not a concept built into Go (so far). This is my absolute №1 “want to have” feature for the future of the language! Maybe in Go 2.0!? Until then I do my best to mimic immutable types with the features I have at hand.
Go is not an OOP language but a multi-paradigm language. Still, you can write code that is very close to OOP by using interfaces and methods with pointer receivers that mutate the state of the receiver object.
func (emailAddress *EmailAddress) Confirm() {
emailAddress.isConfirmed = true
}// somewhere elseemailAddress.Confirm()Mutability can be problematic. If a reference to an object A is held by multiple other objects in a service — B and C — then if B mutates A there will be surprises for C. Such problems are hard to debug and the simple solution is to avoid mutability.
For sure it is possible to implement immutability with pointer receivers:
func (emailAddress *EmailAddress) Confirm() *EmailAddress {
changedEmailAddress := &EmailAddress{
value: emailAddress.value,
isConfirmed: true,
}
return changedEmailAddress
}But then there is no reason to have a pointer receiver and such methods should be implemented as value receivers which make implicit copies of the receiver object. As we can see the code is more compact.
func (emailAddress EmailAddress) Confirm() EmailAddress {
emailAddress.isConfirmed = true
return emailAddress
}Probably you spotted that in the pointer receiver example a reference is returned, whereas in the value receiver example a value is returned. This is not a must, but doing it differently could be a bit confusing.
I need to talk about references vs. values a bit more because references in Go can be nil and now we meet one of the Go developers’ best friends — the nil pointer exception. As Go does not have exceptions this is actually a nil pointer panic. I’ll repeat the code from above, this time in full-blown reference type style.
type EmailAddress struct {
value string
isConfirmed bool
}func BuildEmailAddress(emailAddress string) *EmailAddress {
return &EmailAddress{
value: emailAddress,
}
}func (emailAddress *EmailAddress) Confirm() {
emailAddress.isConfirmed = true
}// somewhere elsevar emailAddress *EmailAddress // this is a typed nil
emailAddress.Confirm() // BOOM - panic because of nil pointerTo make things a bit more interesting — it is not the call to a pointer receiver methods of a nil object that causes the panic — but the method trying to access a property (isConfirmed) of the nil object. So this following code would work fine (ignore the ugliness), even if one or both email addresses are nil:
func (emailAddress *EmailAddress) Equals(other *EmailAddress) bool {
if emailAddress == nil && other != nil {
return false
}
if other == nil && emailAddress != nil {
return false
}
if emailAddress == nil && other == nil {
return true
}
if emailAddress.value != other.value {
return false
}
return true
}To avoid those panics you typically put nil pointer checks into methods that use reference type objects coming in from the outside (via input parameter or by getting it via a method call).
There is a way to avoid that: Just put interfaces on all objects, make the structs unexposed (private), and pass interfaces instead of concrete types around. Outside of the package which defines the object nobody could create them without using the exposed factory methods.
type EmailAddress interface {
Confirm()
}
type emailAddress struct {
value string
isConfirmed bool
}
func BuildEmailAddress(emailAddressValue string) *EmailAddress {
return &emailAddress{
value: emailAddressValue,
}
}
func (emailAddress *emailAddress) Confirm() {
emailAddress.isConfirmed = true
}// somewhere else in a different package// works fine, receives an interface
emailAddress := BuildEmailAddress("john@example.com")// does not work, because it is not exposed
emailAddress := emailAddress{}But there is a little problem with this approach — we have just introduced another type of nil-ness! The interface is public, everybody can create nil interfaces.
// in some other packagevar emailAddress EmailAddress // a type nil interface
emailAddress.Confirm() // BOOM - nil pointerApart from not protecting against nil pointers — interfacing everything is overkill. So this is not a solution I want to use (I tried it).
Sidenote: Returning interfaces for services is fine. Some people think — based on what Dave Cheney tweeted here which was repeated often without nuance — that you should always “accept interfaces, return structs” ignoring what “Effective Go” says about Generality.
After experimenting with all the possibilities I finally came to the conclusion that all my data type objects shall be value types, no exception! They all have one or multiple factory methods as the only allowed way to create them. They all are exposed types but have private properties. If they have mutation methods those return copies.
This leaves one loophole because the types are public and can be created empty anywhere.
type EmailAddress struct {
value string
isConfirmed bool
}// somewhere else// either
var emailAddress EmailAddress// or
emailAddress2 := EmailAddress{}// both create the same thing, a value object of type EmailAddress
// with default values of ["", false]In Go this is actually called zero value — each type has one. So now instead of checking for nil pointers, I would have to check for zero-ness!?! With the available features of Go, there is no perfect solution to this problem. I solve it in a different way, which is “by convention” and structure of code.
Only the boundaries of my Application — the sole places that accept scalar values — create such data type objects. And I trust them while they travel through the stack. I will show this in detail in a later post in this blog series!
One comment about performance here. The object copying that is happening for value receivers can have some performance penalty. In such cases, reference type objects with pointer receivers might be better. But remember premature optimization. Actually, it is even a bit more complicated and value receivers can even be faster. ;-)
Why do I start with the Domain layer?
The Domain is where your business logic lives — ideally only there! In other words, all business decisions should be made in this layer. Sometimes it’s hard to avoid that some business logic bleeds into the Application layer and sometimes it’s not worth the price to try to avoid that. On the other hand, if we start with Infrastructure (repositories and such things) right ahead, chances are that there is bigger trouble. If infrastructural concerns bleed into the Domain then our Domain model is influenced and tied to those technical details and our separation of concerns gets wishy-washy. Even worse, we might spend a lot of time implementing Infrastructure and solving issues there — just to find out that our Domain model is wrong or is not delivering useful outcomes. We want to solve the most important problems first!
Tobias Goeschel has a great talk about Domain Prototyping on YouTube :-)
Full examples of all my Domain objects
Some generic stuff
I’m using the excellent cockroachdb/errors library to mark and wrap my errors and I have abstracted MarkAndWrapError (see below) in a shared function to save some repetition. The marking allows me to test for certain expected error types or map to http errors in my gRPC and REST handlers. My error handling concept is still far from being complete!

The structure of my Domain “layer”
Let me describe why things are structured this way before we look into concrete implementation examples. I’ll unfold the nested sub-packages as we go.

The domain package contains only Commands and Events, everything else is in sub-packages. They are the messages that go in and out, so they are the contracts of the Domain layer. They communicate the capabilities of the Domain!
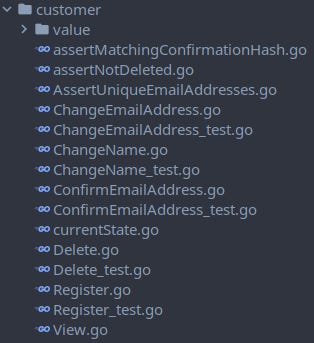
The customer subpackage contains the Customer Domain model. It consists of pure functions (e.g. Register, ChangEmailAddress, …), a struct into which the currentState is projected from the EventStream, the View my model offers, and some assertion functions (policies). The Aggregate is the sum of all the functions plus the currentState. Each public Customer function also has a test. More on my testing strategy in a later post in this series.
Hint: The two assert methods with lowercase file names should signal that they are unexposed, so only visible in the
customerpackage. Same goes forcurrentState. I am not yet sure if I will keep this naming sub-convention.
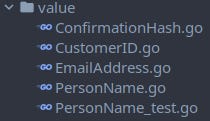
All Value Objects which are part of a Customer live in another subpackage named value. I have to do this because in Go circular dependencies are not allowed. If I would put the Value Objects into the customer package then Commands and Events in domain would import the Value Objects from customer and functions in customer would import Commands and Events from domain. Having them in a subpackage additionally gives more privacy for the Value Objects. Not even functions of the Customer Aggregate can access private parts or create/modify a value without using the proper methods.
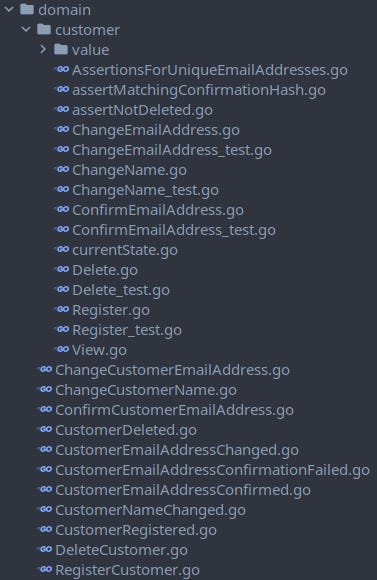
This whole structure is one of many experiments I’m running and I might change my mind about it in the future.
Possible simplification: Just put all the files in one package
domain/customer.
Pro: More idiomatic Go, simpler structure, no circular dependencies.
Con: Big package, harder to spot things, does not work when multiple Aggregates share Value Objects, might be confusing to havecustomer.RegisterCustomer(command) andcustomer.Register(Aggregate function).

CustomerIDhas another type of factory method apart fromBuildandRebuildwhich isGenerate.Only the
Buildfactory method does input validation, it might also do input normalization in the future, e.g. trimming whitespace.The
Rebuildmethod is for cases where the input is ultimately trusted. E.g. for unmarshaling Events, which are built with Value Objects internally.All my single property Value Objects have a getter method
String() string. Not beautiful butValue()orID()IMHO would not be more speaking, would they!?
Possible simplification: Make all properties public.
Pro: No getter methods necessary, more idiomatic Go (?).
Con: No protection against building or modifiying Value Objects without using the proper methods (immutability).
Domain Events

Events have 2 factory methods, one with
Buildand one withRebuild. Same reasoning as for Value Objects,Rebuildis only used for unmarshaling, which is completely handled in the Infrastructure layer, so the Events have no direct knowledge of this concept.Internally they are built from Value Objects, no scalars.
A note about the
IsFailureEvent() boolandFailureReason() errorgetter methods. My Aggregates don’t return errors (with one little exception you will see later), instead, they produce error events if a Domain policy or assertion was violated. Such an error event isCustomerEmailAddressConfirmationFailed. I let the Events tell if they are error Events — if true they also return a reason — so that I don’t have to switch/case on the type in my CommandHandler (Application service). The CommandHandler returns errors to the client in case an error Event was raised.Events are my only data types that fulfill an interface — named
DomainEvent— so that my Event Store can be agnostic of concrete Event types. More about the Event Store in some later posts of this series.The
DomainEventinterface looks like this:
package es
type DomainEvent interface {
Meta() EventMeta
IsFailureEvent() bool
FailureReason() error
}So each Event needs an additional getter method
Meta() EventMeta
EventMeta is part of a shared package named es and looks like:
Possible simplification: Make all properties public.
Pro: No getter methods necessary, more idiomatic Go (?).
Con: No protection against building or modifiying Events without using the proper methods (immutability).Further “bigger” simplification: Annotate the struct with tags for marshaling/unmarshaling from/to JSON.
Hint: This crosses (my) layers because I put the serialization into the Infrastructure layer — and it has further consequences:
The Value Objects contained in the Events would also need public properties with annotations, which would produce superfluous nodes in the JSON objects for “single property” Value Objects, e.g.: {…, id: {id: “12345”}, …}.
To avoid that each Event would need a
MarshalJSON() ([]byte, error)and aUnmarshalJSON([]byte) errorpointer receiver method (or some Value Objects would need such methods).An alternative would be to build the structs of the events with scalar properties which are annotated for serialization — and then rebuild each Value Object in the Events’ getter methods. But then the getters should be the only way to access the Event properties, while technically the properties are accessible and don’t need getters. This seems dangerous and confusing for me.
Pro: Saves some code (in Infrastructure layer), is Go idiomatic, uses Go’s built in magic for serialization.
Con: Gives up separation of concerns. Not much code is saved in case MarshalJSON and UnmarshalJSON are implemented. With scalar properties (see alternative) we get confusing code that can easily be used in a wrong way.
Commands

My Commands are quite boring DTOs / message types.
Possible simplification: Make all properties public.
Pro: No getter methods necessary, more idiomatic Go (?).
Con: No protection against building or modifiying Commands without using the proper methods (immutability).
Event-Sourced Aggregates
Finally, it gets juicy! My Aggregate used to be implemented in OOP style with inline state in the past. My little project is event-sourced and I decided a while ago that I want to implement a functional core. Event-Sourcing is quite functional by nature, so I decided that my Aggregate will only consist of functions! My first functional version did not even have a state object. It simply projected all necessary properties into local variables. Not long ago I introduced a currentState object — which is unexposed — so only visible inside the Domain subpackage customer in which my Aggregate lives.
Let’s have a look at the currentState struct first:

The factory method
buildCustomerStateFrom(eventStream)receives a list of Events as input, uses Go’s type switching over interface types, and projects the properties from the event’s payload — nothing fancy.The
currentStreamVersionis projected from each event in the stream — which should be ordered by ascending versions — given my Event Store does a good job.The state projection is reused in my View as you will see soon.
The first Aggregate function that will ever be executed in the lifecycle of a Customer is Register.

There are no constraints to check and no idempotency to be handled, so all it does is turning the payload of the Command into an Event.
A more interesting case is ConfirmEmailAddress because it is (currently) the only function of the Customer Aggregate that returns an error event if a policy is not fulfilled.

Each Aggregate function except
Registermust first project the currentState from the history of events — theeventStream. This could be done outside of the Aggregate, for example in the CustomerCommandHandler, or even in the CustomerEventStore. The problem with that approach is again that Go has limited visibility options — the missing immutability. I certainly don’t want to make the state exposed! In functional languages with immutable types, the signature of this function might look likeConfirmEmailAddress(state, command) DomainEvents.
Anyways — not a big deal to call the state factory inside of each Aggregate function.Next is a check if the Customer is (soft) deleted by using the policy
assertNotDeletedwhich returns an error in this case. This is the only type of error my Aggregate functions can return. It makes no sense for me to use an error event here. Still, I want the Domain to make this decision and not the CustomerEventStore or some other thing outside of the Domain layer. I guess the current implementation is a bit of a compromise!After doing the basics we see another policy in action.
assertMatchingConfirmationHashchecks if the supplied confirmation hash matches the one that was generated for the current email address. If it does not match the Aggregate returns aCustomerEmailConfirmationFailedevent with a failure reason.Now it’s time to check for idempotency. If the email address is already confirmed no event happens.
Otherwise it returns a
CustomerEmailAddressConfirmedEvent.The code in the two policies used above is very short and primitive and I could just put that logic into the Aggregate functions. There are two reasons to extract them:
to make the Domain logic explicit and visible
to avoid duplication of code that makes business decisions
Those two policies look like this:


There is another policy with assert in the name, which is a bit harder to explain:

The factory method
BuildUniqueEmailAddressAssertionsis used by the Event Store in the Infrastructure layer.It creates a list of
UniqueEmailAddresseAssertionobjects that determine what work has to be done (desiredAction)and which email addresses are involved (emailAddressToAdd,emailAddressToRemove).Those desired actions are derived from the
recordedEvents.I built this because such decisions should be made in the Domain layer. The business logic should live there and not in Infrastructure. Having this implementation the Domain decides which
recordedEventsshould issue which actions to make sure each email address is unique throughout all Customers.Now there is a type of thing we have not seen so far, a function type:
type ForBuildingUniqueEmailAddressAssertions func(recordedEvents ...es.DomainEvent) UniqueEmailAddressAssertionsFunctions are first-class citizens in Go and can be used like “functional interfaces”.
By using this function type in signatures of collaborators it defines a contract so that any function that fulfills the signature can be injected — just like with usual interfaces.
I will explain the concept — and why I use it — in depth when I write about the Application layer. I’ll also explain the naming schema starting with For (which has to do with Hexagonal Architecture).
I added this function type to make the dependency of the Event Store to such a function explicit. Previously the Event Store was simply calling the function inline, now it is injected.
Having multiple things in one file here (function type, struct, slice, factory method, …) is something I do sometimes to encapsulate a whole concept.
Views
Another citizen in my Domain model is the View which is used to answer “CustomerByID” queries from clients.

I am not defensive with Views and simply expose the properties.
You can see that I reuse
buildCurrentStateFromwhich builds the samecurrentStatestruct that is used by the Aggregate functions. This way I can’t miss to add projections if I add Events. Basically the View is just mapping thecurrentStateinto a different representation. One might think this is display logic and should live in Infrastructure, but it isn’t. There is another mapping to the actual response returned from the http layers (gRPC and REST). The View’s Domain logic decides which properties are there. It skips the confirmation hash for example. It also flattens the person name intoGivenNameandFamilyName.Should I ever need additional Views they will get more specific names.
Why no interfaces defined by the Domain?
My persistence interfaces are quite technical, due to the nature of event-sourcing and the functional implementation of my Aggregate. The persistence interfaces only offer append, retrieve, and purge. Those are not Domain concepts I want to communicate. That’s why I put them into the Application layer. Currently, there are no other services whose interfaces could be defined by the Domain. The question if/when to put such interfaces into Domain/Application is rather controversial in the Domain-Driven Design community. I make this decision case-by-case. If they represent Domain concepts I tend to put them there.
Sidenote: I experimented with rather complex solutions that would hide the event-sourced nature of a Customer when it comes to persistence. I decided that the complexity was not worth it.
The runnable source code is available on GitHub
Hint: This links to a branch that is “frozen” so it matches what I wrote in the blog article(s). Beware that the code, same as the original article, is from 2020 - nevertheless it should run fine.
The other parts of this series are here:
Part 1 - Introduction to the domain, the bounded context, and the business usecases
Part 3 - How I structure my application according to Hexagonal Architecture aka. Ports&Adapters
Thank you for your time and attention! :-)
My articles / subscriptions here are for free, but you can support my work by buying me a coffee.